각종 정렬 알고리즘 모음
. 힙정렬(Heap Sort)이란?
-. 힙은 전이진 트리에서 임의의 노드는 언제나 자식노드들 보다 큰 값을 갖는 구조이다.
-. 여러 개의 노드들 중에서 가장 큰 키값을 가지는 노드나 가장 작은 키값을 가지는 노드를
빨리 찾아내도록 만들어진 자료구조이다.
-. 완전 이진 트리의 하나로서 각각의 노드는 유일한 키값을 가진다.
-. 트리구조에서는 Root가 가장 큰 값을 보유하고 있다.
-. 우선순위 큐의 일종으로 우선순위가 높은 요소를 효율적으로 선택할 수 있는 자료구조이다.
2. 우선순위 큐(Priority Queue)란?
-. 큐에 저장된 자료는 순위에 의해 순서가 유지되는 자료구조의 추상적인 개념이며 다음
일곱가지의 동작이 정의되는 경우가 대부분이다.
1) 생성(Construct) – 주어진 N개의 자료로 우선순위 큐를 생성한다.
2) 삽입(Insert) ---- 우선순위 큐에 새로운 자료를 삽입한다.
3) 제거(Remove) ---- 순위가 가장 높은 자료를 제거한다.
4) 대치(Replace) --- 순위가 가장 높은 자료와 새로운 자료를 대치한다.
5) 변경(Change) ---- 자료의 순위를 변경한다.
6) 삭제(Delete) ---- 임의의 자료를 삭제한다.
7) 결합(Join) ------ 두 우선순위 큐를 결합하여 큰 우선순위 큐를 만든다.
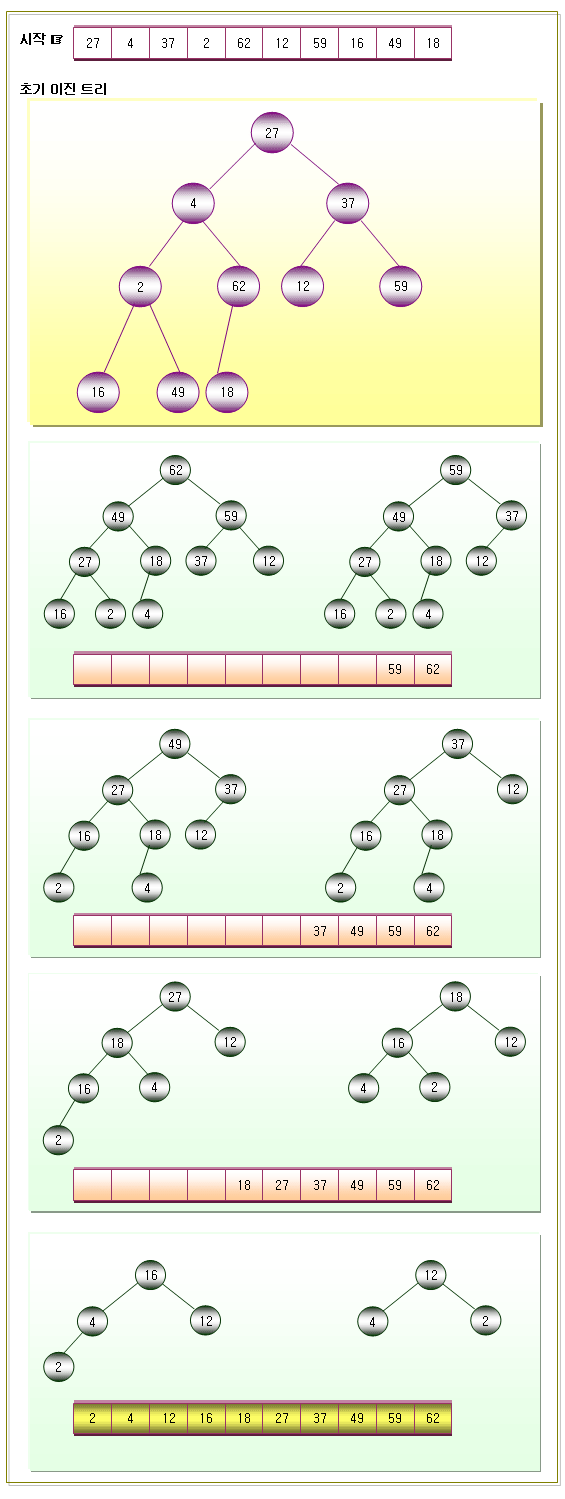
3. 힙정렬을 이용하여 오름차순으로 정렬하는 방법
4. 힙정렬의 비교회수
-. 비교회수 공식 : 2N log N
5. 힙정렬의 연산시간
-. 연산시간 공식(평균) : 0(n log n)
-. 연산시간을 표기하는 방법은 일반적으로 사용하는 O표기법인데, 이 O표기법은 ‘최악의 경우’
(Worst Case)에 대한 연산시간을 나타낸다.
6. 힙정렬의 장점
-. 다른 정렬들에 비해 최악의 연산시간일 경우에도 0(n log n)으로 적게 든다.
-. 추가적인 메모리를 필요로 하지 않는다.
7. 힙정렬의 단점
-. 데이터 구조에 따라서 다른 정렬보다 조금 늦게 정렬될 수도 있
퀵 정렬 알고리즘
1. 퀵정렬(Quick Sort)이란?
-. 교환정렬의 일종이며 분할-정복법(divide and conquer)에 근거한다.
-. 정렬할 리스트를 두개로 분할하고 정렬하는 방법이다.
-. 축(pivot)값을 기준으로 정렬하는데, 축값을 중심으로 축값보다 큰 값은 오른쪽 리스트에
작은 값은 왼쪽리스트로 이동시킨다. (첫번째의 데이터를 축값으로 한다.)
-. 오른쪽 리스트와 왼쪽 리스트부분은 독립적인 단위로 정렬하여 오른쪽 리스트부분에 대한
새로운 분할 축값을 선택하여 두 부분으로 분리하고, 왼쪽 리스트부분 역시 새로운 축값을
선택하여 두 부분으로 분리하는 과정을 반복하는데 리스트들은 재귀적 방법으로 각각 재배열
하는 방식이다.
-. 각 분할 자료개수가 1이 되면 정렬은 완료된다.
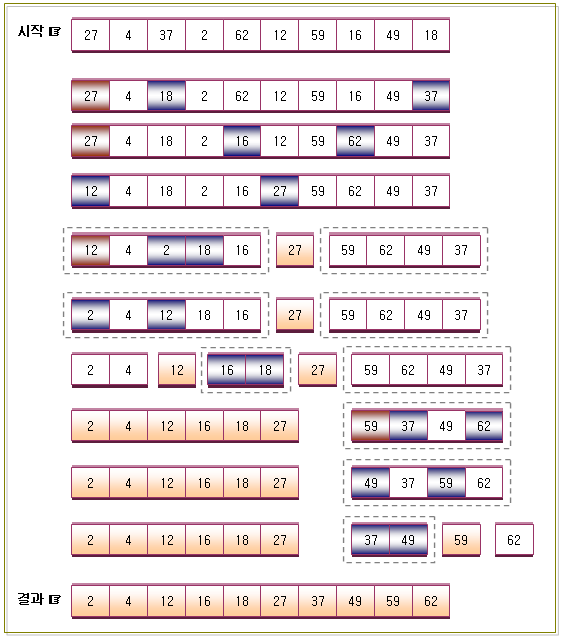
2. 퀵정렬을 이용하여 오름차순으로 정렬하는 방법
3. 퀵정렬의 비교회수
-. 최선일 경우의 비교회수 공식 : N - 1
-. 최악일 경우의 비교회수 공식 : N(N – 1)/2
-. 위의 그림을 보시면 아시겠지만 제일 처음에는 (N – 1)번을 비교하고,
그 다음에는 (N – 2)번 만큼 비교하고, 그 다음은 (N – 3)번을 비교하면서 비교회수가 1이 될
때까지 이 작업을 반복할 것이다.
-. 비교회수는 (N – 1) + (N – 2) + (N – 3) …… + 1 이 될 것이다.
최대 (N – 1)번을 수행할 것이며, 각 패스가 수행할 때마다
수학식으로 표현하면 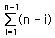 이므로 공식은 N(N – 1)/2 이런 공식이 성립된다.
이므로 공식은 N(N – 1)/2 이런 공식이 성립된다.
4. 퀵정렬의 연산시간
-. 연산시간 공식(평균) : 0(n log n)
-. 연산시간 공식(최악이 경우) : O(n²)
-. 연산시간을 표기하는 방법은 일반적으로 사용하는 O표기법인데, 이 O표기법은 ‘최악의 경우’
(Worst Case)에 대한 연산시간을 나타낸다.
5. 퀵정렬의 장점
-. 정렬할 데이터가 이미 준비되어 있고 모든 데이터들을 정렬해야 할 경우에 가장 빠른
수행속도를 보여준다.
6. 퀵정렬의 단점
-. 축(pivot)값이 같은 것끼리는 순서관계가 파괴된다.
(중요한 데이터의 경우에는 퀵정렬을 사용하지 않는 것이 좋다.)
-. 안정성이 없다.
| 쉘 정렬 알고리즘 |
. 쉘정렬(Shell Sort)이란?
-. 자료를 여러 부분으로 분할하여 적절한 크기로 나누어진 배열들을 간단한 삽입정렬 등을 이용
하여 정렬한 후 합쳐가면서 다시 정렬하는 방식이다.
결국, 전체를 정렬하는 방식이며 자료들을 분할하는데 있었어 너무 잘게 분할하거나 너무
엉성하게 분할하면 부분 정렬 후 병합의 어려움이 생길 수 있다.
(적당한 매개변수(h)를 정하고 h만큼 떨어져 있는 값을 비교하여 h가 1이 될 때까지 반복)
-. 멀리 떨어진 자료와 비교할 때 멀리 떨어져 있는 값들만 비교하고 떨어진 정도를 점차 줄여나
가다가 마지막에 1이 되면 정렬이 완료된다.
2. 쉘정렬에서 자료를 분할하는 평균적인(자주 사용하는) 공식
-. 자료를 몇 개로 분할해야 되는지의 기준(increments 또는 h-sequence라고 부른다)이 전체적인
성능에 결정적인 영향을 미친다.
(일반적으로 떨어진 정도를 구하는 것은 여러 가지 방법이 있으며 경우에 맞게 정하면 된다.)
-. 평균적인 공식
h(1) = 1;
h(i + 1) = 3 * h(i) + 1;
로 하면 좋은 결과를 얻을 수 있으며, 이 순열은 1, 4, 13, 40 …의 역순으로 된 순열이다.
만약, 배열의 크기가 60일 때는 먼저 40개의 부분배열로 나누어 삽입정렬을 이용하고,
13개의 부분배열로 나누어서 삽입정렬을 이용한다.
배열을 다시 4개의 부분배열로 나누어 삽입정렬을 한 후 마지막으로 배열전체에 삽입정렬을
한다.
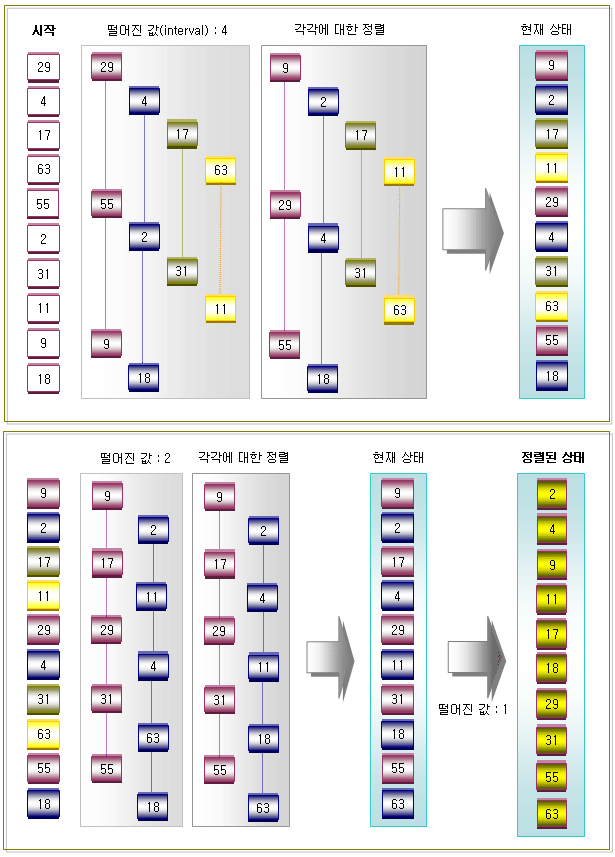
3. 쉘정렬을 이용하여 오름차순으로 정렬하는 방법
4. 쉘정렬의 비교회수
-. 순열 h가 1, 4, 13, 40 … 일 때의 비교회수
5. 쉘정렬의 연산시간
-. 연산시간 공식 : O(n²)
-. 연산시간을 표기하는 방법은 일반적으로 사용하는 O표기법인데, 이 O표기법은 ‘최악의 경우’
(Worst Case)에 대한 연산시간을 나타낸다.
-. 수학식으로 표현하면 아래와 같다.
= n(n – 1) – (n – 1)/2 = n(n - 1)/2 이므로 Worst Case는 n(n – 1)/2 이다.
그래서 연산시간은 O(n²)가 되는 것이다.
6. 쉘정렬의 장점
-. 입력자료에 상관없이 뛰어난 속도를 보인다.
-. 삽입정렬은 왼쪽에 있는 자료가 정렬이 되었다는 가정하에 정렬을 하므로, 가장 오른쪽에 있는
자료를 왼쪽으로 삽입하려고 하면 많은 교환이 이루어지는 단점을 보완한 정렬방식이다.
-. 멀리 떨어져있는 자료들이 비교 및 교환될 수 있으므로 어떤 자료가 제 위치에서 멀리 떨어져
있다면 여러 번의 교환이 발생하는 버블정렬 방식의 단점을 해결한다.
7. 쉘정렬의 단점
-. 기준(h)을 정하는 방법에 따라 알고리즘의 성능이 달라진다.
-. 안정성이 없다.